Debian Janitor: How to Contribute Lintian-Brush Fixers
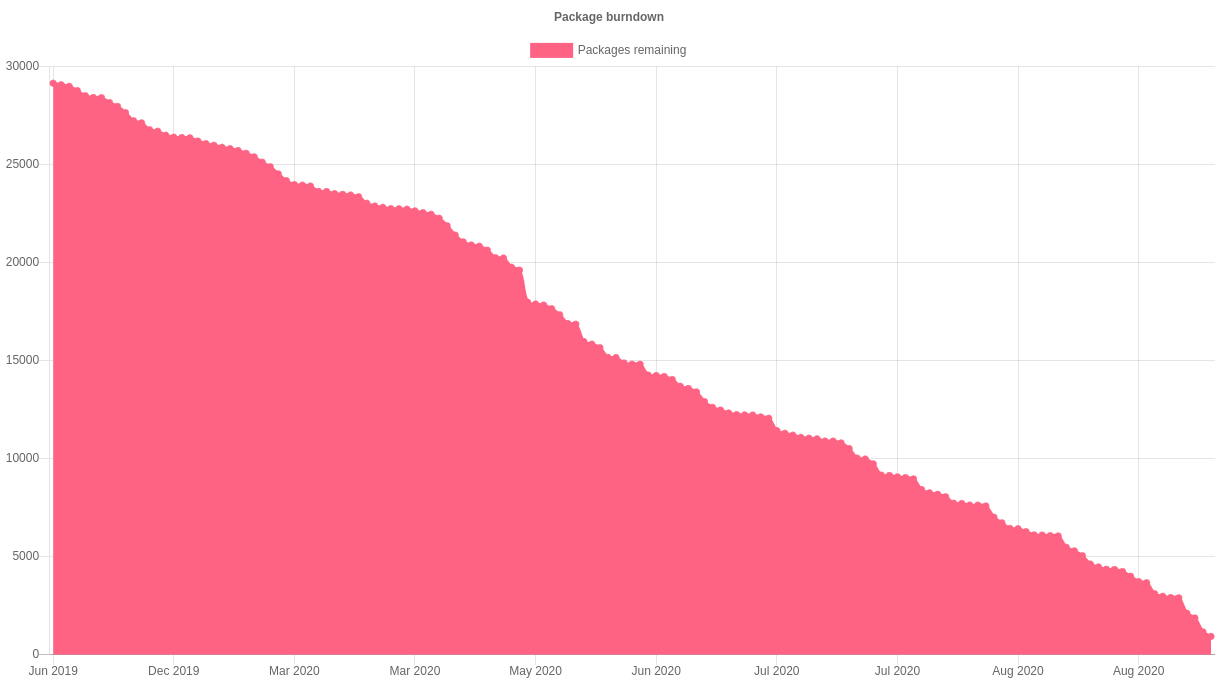
The Debian Janitor is an automated system that commits fixes for (minor) issues in Debian packages that can be fixed by software. It gradually started proposing merges in early December. The first set of changes sent out ran lintian-brush on sid packages maintained in Git. This post is part of a series about the progress of the Janitor.
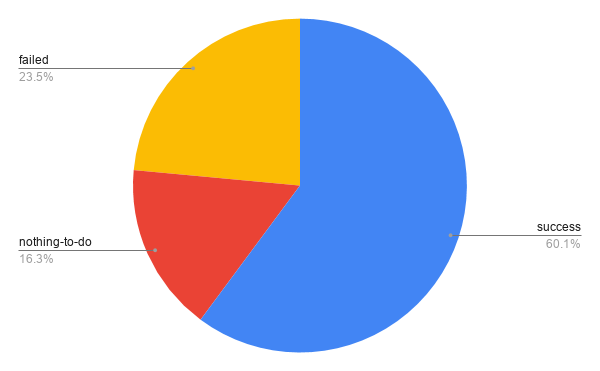
lintian-brush can currently fix about 150 different issues that lintian can report, but that’s still a small fraction of the more than thousand different types of issue that lintian can detect.
If you’re interested in contributing a fixer script to lintian-brush, there is now a guide that describes all steps of the process:
- how to identify lintian tags that are good candidates for automated fixing
- creating test cases
- writing the actual fixer
For more information about the Janitor’s lintian-fixes efforts, see the landing page.